
In der heutigen Vorlesung waren Herr Sven Koesling und Michael Gasser zu Gast. Sven Koesling ist Leiter der Bibliotheks-IT-Services der ETH-Bibliothek und Michael Gasser ist Leiter der Archive. Die beiden präsentierten einen Einblick in die Praxis.
Die ETH hat eine Menge von Software, Technologien und Webseiten. Daraus führt, dass die ETH auch mit vielen verschiedenen Metadaten arbeitet, welche alle miteinander verbunden sind. Die nachführende Grafik zeigt eine Übersicht.
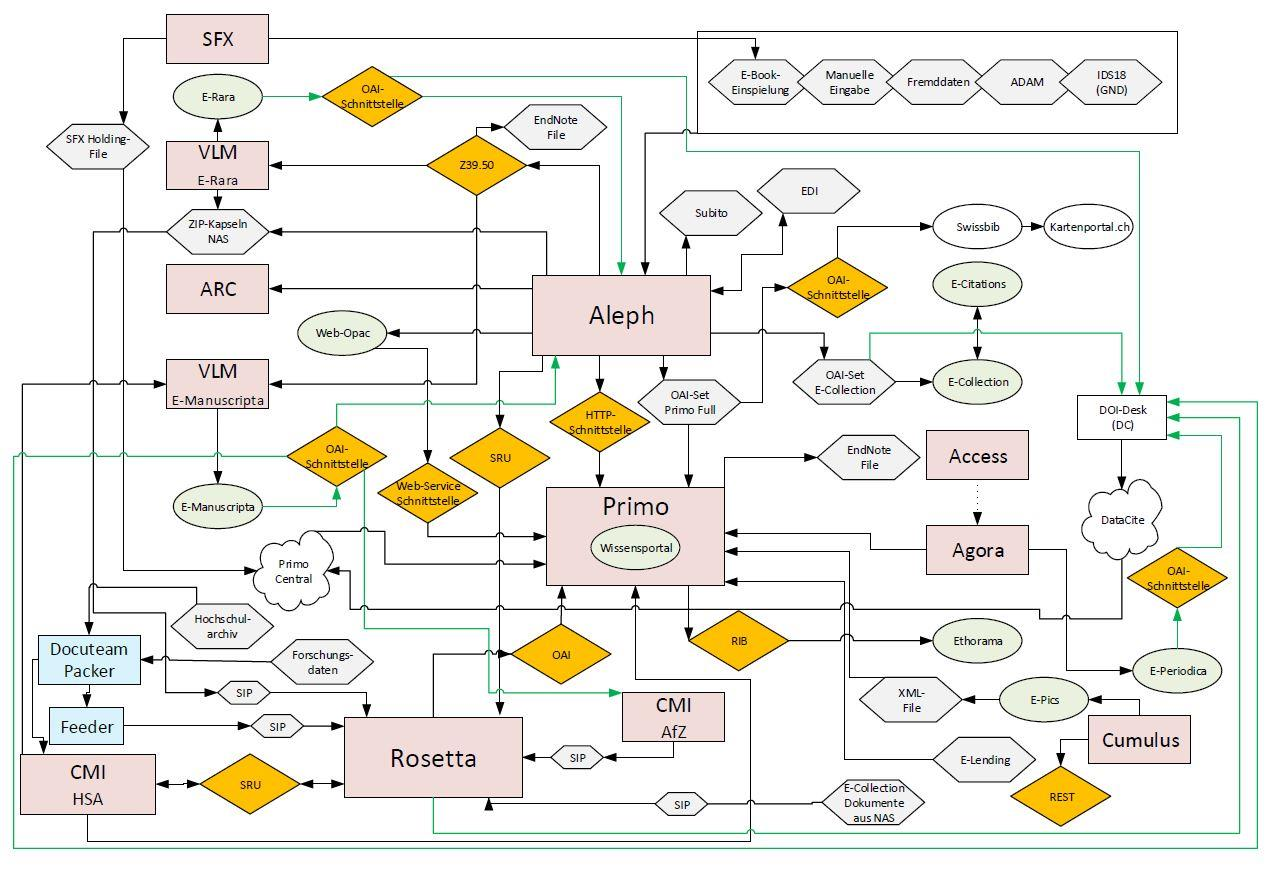
Das Ganze ist ziemlich kompliziert und am Anfang fragten wir uns alle, wieso die ETH denn so viele verschiedenen Programme und Metadaten benötigt.
Das Tagesprogramm war umfangend, deswegen werde ich auf zwei Themen eingehen. Herr Koesling begann mit der Entwicklung des Integrated Library Systems, bei der ETH ist dies die Software Aleph. Dies ist ein OPAC System. Er zeigte auf, wie es zu dem OPAC kam und was dessen Schwächen sind. Um gewisse Schwächen verstehen zu können, hielt er einen kleinen Exkurs zum Thema Datenbanken.
Datenbanken ist etwas, was mich persönlich sehr interessiert. Im Unterricht hatten wir bisher nur von relationalen Datenbanken gehört, sein Exkurs war also sehr informativ. Die Datenbank hinter dem Aleph ist auch eines seiner Probleme. Eine relationale Datenbank ist starr und ist kaum veränderbar. Das Einzige was machbar ist, ist die Datenbank zu erweitern, was allerdings die Datenbankstruktur so kompliziert macht, dass nur noch der Herstellter einen Überblick hat.
Ein grosser Fehler vom Aleph ist, dass die Felder nicht atomar sind. Mich hat dies ziemlich überrascht, da dies so etwa die wichtigste Regel betreffend Datenbanken ist. Felder sind atomar. Punkt. Da gibt es keine Ausnahmen. Zudem hat der OPAC keine Indexe, was die Suche sehr langsam macht. Aleph basiert auf einer Oracle Datenbank, was den Nachteil hat, dass die ETH auf Oracle angewiesen ist.
Fazit der Präsentation war mehrheitlich: der OPAC ist veraltet, heute kaum noch anpassbar, langsam und aufwändig. Aber: der OPAC wird trotzdem noch gebraucht.
Als weiteres Thema präsentierte Herr Koesling das Discovery tool der ETH-Bibliothek, Primo. Um Aufzuzeigen, wie man vom OPAC auf das Discovery System kam, zeigte er nochmals die Schwächen des OPAC auf, welche nicht wenige sind.
Nun, auch Primo läuft mit einer Oracle Datenbank. So schnell kommt man von Oracle nicht weg, wie es scheint. Primo bezieht seine Daten über Pipes, das heisst, die Daten werden gesucht, normalisiert und im eigenen Format PNX abgespeichert. Primo’s Datenbank verfügt jedoch über einen Indexer, und da die Mehrheit der Daten von externen Quellen stammen, ist die Datenbank nicht so komplex wie die vom Aleph.
Primo anzupassen ist jedoch aufwändig. Man muss die Files von Hand anpassen. Bei Updates bedeutet dies hoher Aufwand. Die ETH hat deswegen einen eigenen Kreislauf konzipiert, wie sie die Software updaten und anpassen. Sie erstellen von der aktuellen Software eine Kopie, updaten diese Kopie und setzen die Anpassungen um. Danach wird getestet und wenn alles in Ordnung ist, wird das Original einfach von der Kopie ersetzt. So hat die IT keinen Zeitdruck, es wird keine Software mit Fehler freigestellt und die Benutzer kommen von dem Wechsel so gut wie nichts mit.
Besonders interessant fand ich die Einspeisung der Archivdaten in Primo. Die Einspeissung hat viel Informationsverlust mit sich, da die beiden Systemem mit verschiedenen Metadatenstandards arbeiten. Wie wir schon gelernt hatten, gibt es Mappings, um von einem Standard in den andere zu übersetzen. Dabei kann es allerdings zu Datenverlust kommen. Dies ist auch bei der ETH der Fall.
Ich persönlich finde es nicht nötig, im Discovery Tool die Archivgüter einzupeisen, aber ich bin da eher eine Minderheit. Ich denke, die Mehrheit der Benutzer von Primo wissen gar nicht, dass sie nach Archivgüter suchen können und selbst wenn, wissen sie nicht für was sie dies gebrauchen können. Benutzer, welche im Archiv nach Dokumenten suchen, sollten eigentlich wissen, wie Archivsysteme funktionieren oder sich dann informieren. Aber wie gesagt, ich bin da eine Minderheit. Sicherlich kann die Einspeisung der Archivdaten in Primo eine Art Marketing Effekt haben. Die Benutzer werden darauf aufmerksam, dass Archivdaten vorhanden sind und überlegen sich beim nächsten Mal vielleicht, ob sie auch dort fündig werden können.
Was mich fasziniert, ist das weiterhin beide Systeme den Benutzer zur Verfügung stehen. Der OPAC und das Discovery Tool, und dass obwohl der OPAC der ETH so viele Probleme gibt, und obwohl 97% aller Benutzer nur ein Suchwort eingeben und das Discovery Tool benutzen. Nichts desto trotz gibt es Benutzer, welche den OPAC benutzen. Wie wir schon gelernt haben, gibt es verschiedenen Arten von Suchen. Entweder man weiss nach was man sucht und will es schnell finden oder man weiss nicht genau was und hofft etwas relevantes zu finden.
Der OPAC und das Archivsystem basieren beide auf Retrievel. Man sucht nach etwas und findet es. Primo basiert auf entdecken und auf dem Serendipity Effekt. Per Zufall findet man eventuell ein Dokument, welches ebenfalls interessant ist. Am Ende jedoch, braucht es beides und ich persönlich finde es toll, dass die ETH Bibliothek auch weiterhin beide Systeme den Benutzer zur Verfügung stellt.
So klärte sich am Schluss auch, wieso die ETH so viele verschiedenen Programme hat.
