
Linked Data ist ein bekannter Begriff, aber was ist denn eigentlich Linked Data? Nun, in unserem Studium hatten wir bereits zwei Module zu diesem Thema.
Linked Data dient der Verknüpfung zwischen Datensilos. Daten werden miteinander verknüpft und der Nutzer erhält dadurch Zusatzinformationen. Ein möglicher Anwendungsfall für Bibliotheken wäre die Anzeige von Zusatzinformationen im Bibliothekskatalog über Autoren. Die Infos stehen nicht in den Katalogdaten, sondern werden über Verweise und Links aus einer Personendatenbank geladen. Ein solches Beispiel ist beispielsweise die GND Datei der Deutschen Nationalbibliothek. In solchen GND-Dateien werden Daten über Personen gespeichert. Die Bibliothek muss also nur darauf verlinken und schon stehen Daten wie Geburtsort, Todesort, bekannte Werke etc. zur Verfügung.
Damit allerdings Linked Data genutzt werden kann, benötigt es eine semantische Auszeichnung der Daten mit einem Vokabular. Ein solches Beispiel ist schema.org, mit welchem Google seine Knowledge Graphs erstellt.
Aber was hat dies nun mit Bibliotheken zu tun? Im Kurs haben wir versucht die praktischen Potentiale von Linked Data für Bibliotheken zu sammeln. Folgende Punkte sind das Resultat:
- Katalogisierungsprinzip (z.B. BIBFRAME)
- übergreifende Suche
- Verwandtes / Zusammengehöriges entdecken
- statistische Analysen
- Einheitlichkeit und Effizient
Ermöglicht werden diese Potentiale durch die Verknüpfung von bisher unverbundenen Datensilos mit Bezug auf gemeinsame Identifier. Das grundlegende Datenmodell ist RDF (Resource Description Framework). Der Austausch wird ermöögicht, in dem man standardisierte Vokabulare wie dcterms, foaf oder bibo benutzt. Die Daten werden als Triple abgelegt und sind über die Abfragesprache SPARQL abrufbar. (Mit SPARQL durfen mir bereits arbeiten und obwohl behauptet wird, dass die Sprache ähnlich wie SQL sei, sehe ich persönlich dies etwas anders…)
Linked Swissbib
Ein solches Projekt ist Linked Swissbib. Interessanterweise hatten ich und meine Kollegen Moreno und Aline uns stark mit diesem Projekt für ein anderes Modul befasst. Am Tag vor diesem Kurs verbrachte ich einen Morgen lang auf der Webseite und war durchaus vertraut damit… ^_^
Die Ziele des Projektes waren folgende:
- Konversion des swissbib data sets in ein RDF Datenmodell (als Grundlage für Datenverknüpfungen)
- Nutze die Möglichkeiten von verlinkten Informationen in eigenen Services und biete sie anderen zur Nachnutzung an
- Verwendung von freier (möglichst erprobter) Software, entwickelt durch vergleichbare Institutionen. Entwicklungen sollten durch andere nachgenutzt werden können
Das Projekt startete 2014, wurde von swissuniversities gefördert und gemeinsam von drei Partnern durchgeführt:
- Haute école de gestion de Genève: Schwerpunkt Datengenerierung
- Hochschule für Technik und Wirtschaft Chur: Schwerpunkt Oberfläche
- Universitätsbibliothek Basel: Schwerpunkt Infrastruktur
Datenmodell und Datentransformation
Das Datenmodell von linked swissbib wurde anhand der Frage: “Was wollen wir auf der Oberfläche anbieten?” nutzergesteuert entwickelt:
- Aggregationsseiten (eigener und angereicherter Inhalt)
- Knowledge Cards (Inspiration: Google Knowledge Graph), jeweils zu Autoren, Werken und Themen
- Erweitertes Autocomplete
Hierzu wurden die etwa 29. Mio. MARC Datensätzen in etwa 125 Mio. Dokumente in JSON-LD umgewandelt und in sechs Konzepte aufgeteilt:
- Bibliographic Resource
- Document
- Item
- Work
- Person
- Organisation
Bibliographic Resource
Um auszuwählen, welche MARC-Felder für das Konzept “Bibliographic Resource” genutzt werden sollen, wurde wie folgt vorgegangen:
- Die am häufigsten vorkommenden MARC Felder werden transformiert.
- Die für die Oberfläche notwendigen MARC Felder werden transformiert.
Daraufhin wurden 22 MARC-Felder ausgewählt. Das folgende sieht beim Beispiel “Jane Austen’s letters” folgendermassen aus:
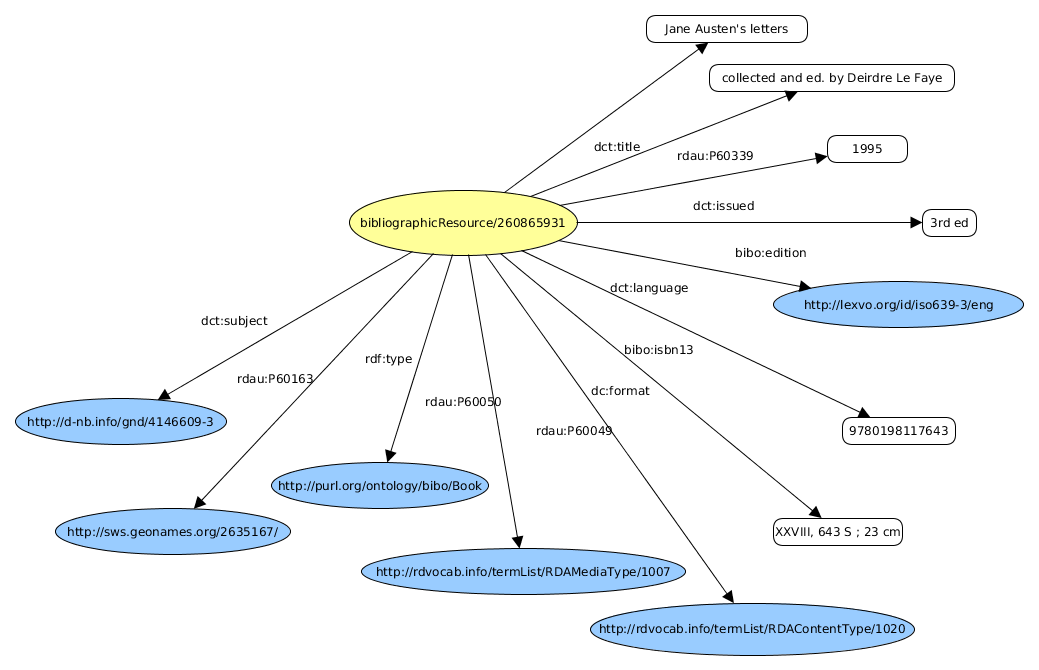
Document und Item
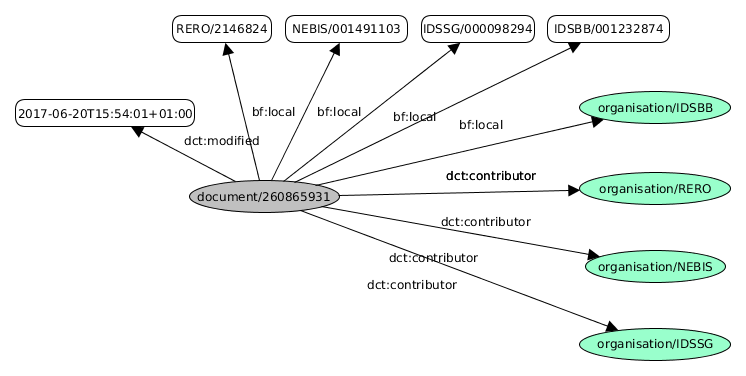
Es erfolgte eine Trennung von bibliografischen Daten und administrativen Daten:
- Document: Metadaten über die bibliografischen Daten
- Item: Exemplar in einer Bibliothek
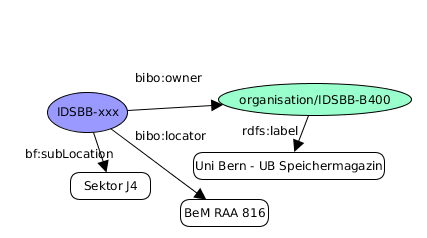
Work
Das Werk-Konzept von Linked Swissbib ist aktuell nicht mit dem Werk aus FRBR gleichzusetzen. Abgebildet werden weitere Ausgaben auf swissbib.ch.
Person und Organisation
Personen werden, wenn möglich, als identisch erkannt und mit einer einheitlichen URI versehen. Die Dublettenerkennung erfolgt über einen “Author Hash” mit den folgenden Kriterien (in dieser Reihenfolge):
- GND
- Name, Titel der Person und Lebensdaten
- Name, Titel der Person und Titel der Publikation
Bei Personen funktioniert die Dublettenerkennung leider noch nicht wirklich, denn im Moment sind etwa 22 Jane Austen’s im System vorhanden, wobei bei nur einem Eintrag wirklich Daten vorhanden sind.
Organisationen werden mit den Kriterien Name, Abteilung, Datum und Ort zusammengeführt, falls dies möglich ist.
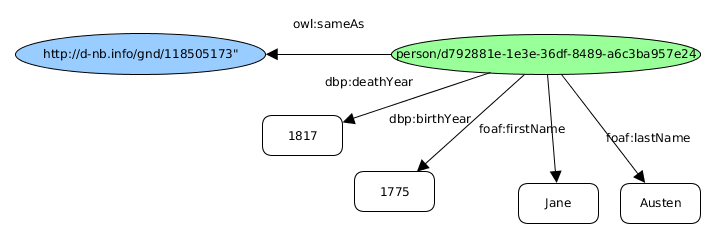
Alles zusammen sieht dies so aus:
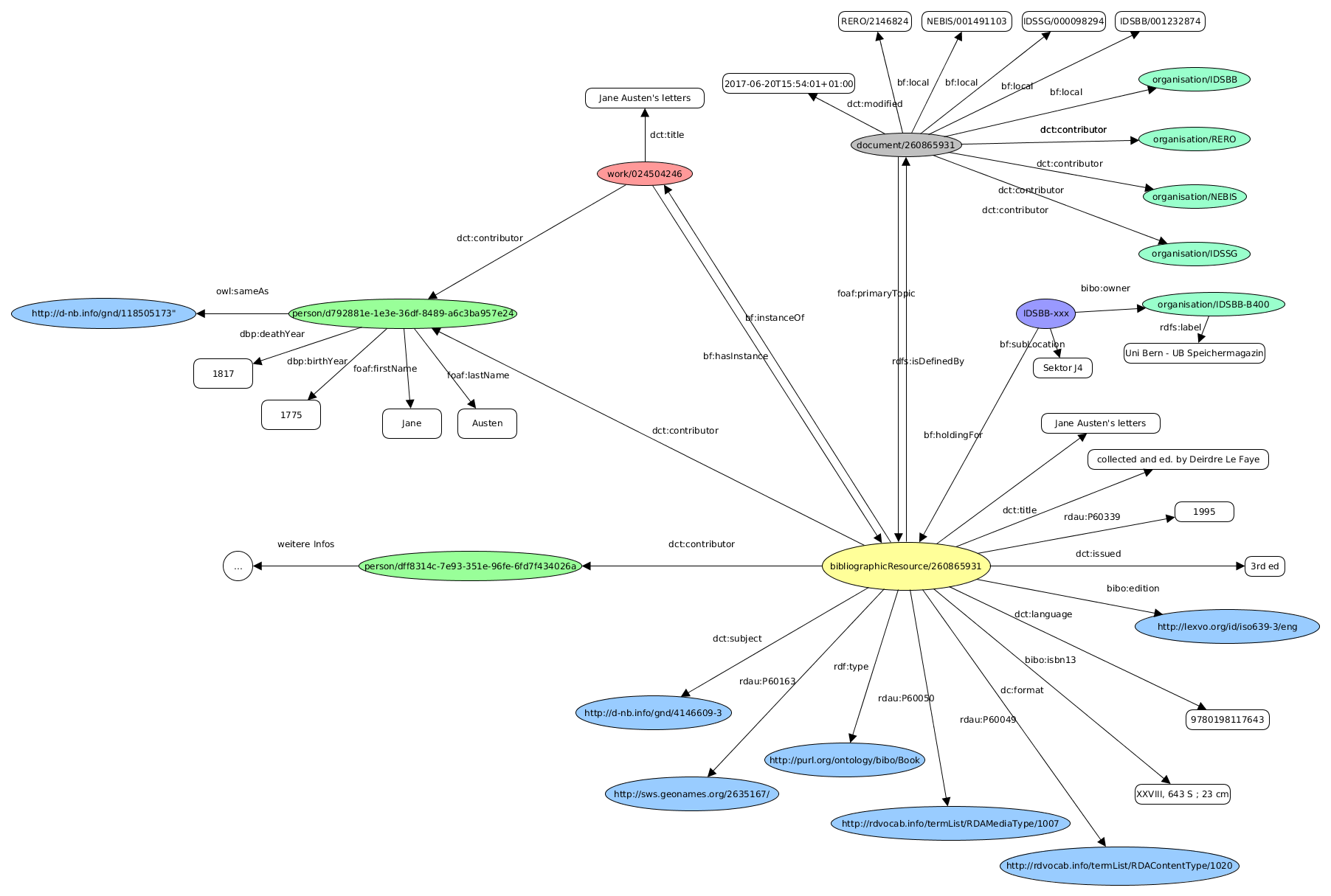
Die Anreicherung erfolgte hier noch nicht. Dies sind alles Informationen aus dem MARC-Datensatz, einfach in einer etwas ansehnlicher Form.
Verlinkung und Anreicherung
In linked swissbib wurden nur Personen verlinkt. Die Person wird mit Informationen aus VIAF und DBpedia angereichert.
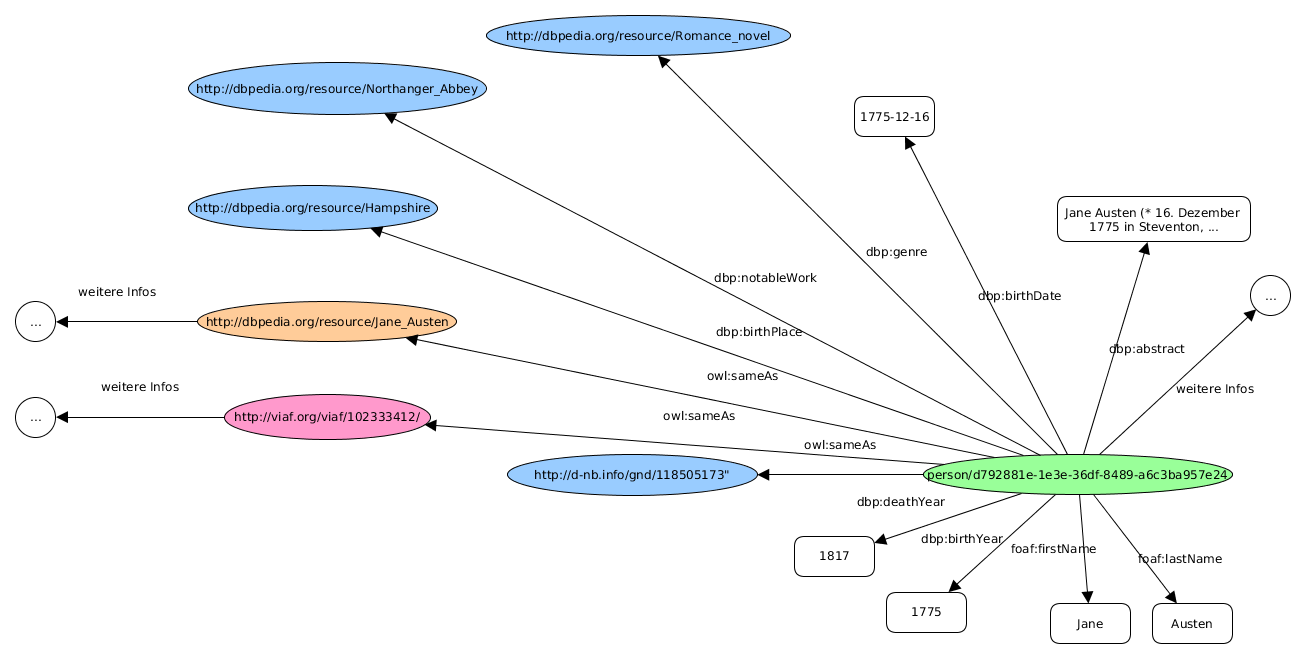
Im Moment befindet sich linked swissbib noch in der Prototyp Phase, das Testsystem soll jedoch in swissbib.ch integriert werden.
