
In der letzten Vorlesung befassten wir uns mit dem Suchindex Apache Solr. Solr ist eine weit verbreitete Software für die Indexierung für Suchmaschinen, zusammen mit Elastic Search. Beides sind Open-Source Produkte, was toll ist.
Bevor wir jedoch mit Solr arbeiten konnten, mussten wir unsere Testdaten alle auf den gleichen Stand bringen. Dafür mussten wir unser Projekt zurücksetzen und mit dem JSON-File des Dozenten neue Anpassungen durchführen. Dies ging leider ziemlich lange und bei mir stürzte OpenRefine ab, also musste ich nochmals von vorne beginnen. Beim zweiten Versuch klappte es dann, ich musste einfach einzelne Schritte nacheinander durchführen. Alles auf einmal war zu viel für OpenRefine.
Nun konnten wir Apache Solr installieren. Dies klappte ganz gut, jedoch ist die Arbeit mit dem Terminal immer noch ein wenig umständlich für mich. Ich bin halt an Benutzeroberflächen gewohnt.
Da Solr mehrheitlich im Hintergrund läuft, sieht das Programm auch nicht wirklich gut aus. Die Oberfläche ist rein für das Testen konzipiert worden, ansonsten kommuniziert Solr direkt mit dem Katalog.
Um uns mit Solr und dem Query Interface vertraut zu machen, führten wir wieder ein Tutorial durch. (http://lucene.apache.org/solr/guide/7_1/solr-tutorial.html#tutorial-searching)
Was mich persönlich ein wenig stört, ist das Solr als Standard die einzelnen Begriffe mit OR verknüpft und nicht wie üblich mit AND. Ich persönlich bin der Meinung, dass mehr Suchbegriffe weniger Resultate liefern sollen, also die Precision erhöhen. Aber ich gehe davon aus, dass man dies später anpassen kann.
Nachdem wir alle das Tutorial durchgearbeitet hatten, erklärte unser Dozent mit Hilfe einer Grafik, was genau die Aufgabe von Solr ist.
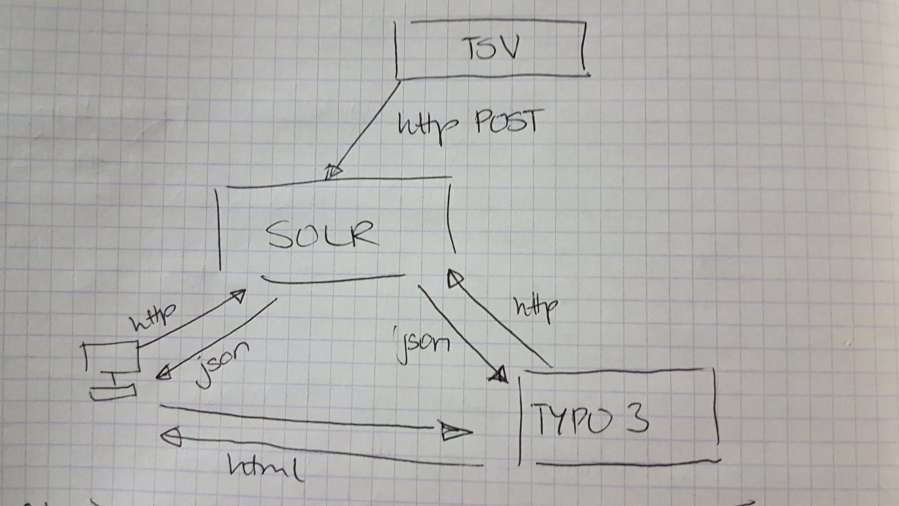
Solr kommuniziert rein mit der Webseite. Die Webseite sendet Anfragen über http und erhält Antwort in Form von einem JSON File. Das Ganze verläuft sehr ähnlich wie PHP und SQL Datenbanken.
Nun – so dachten wir jedenfalls – kann man die Testdaten in Solr einspeisen. Nur leider hatten wir uns zu früh gefreut, denn vorher mussten wir unsere Testdaten noch massieren. (die Daten sind anscheinend gestresst…) Witz beiseite, unter massieren versteht man die Umstrukturierung von MARC21 auf Dublin Core (DC) Felder.
Unter Befolgung einer Anleitung, erstellten wir selbstständig das DC Feld creator und fügten die Inhalte aus dem MARC21 Felder 100a, 100D, 100d und 100e hinzu. Dies klappte ganz gut. Danach versuchten wir selbständig die Inhalte vom MARC21 Feld 245 ins DC Feld title einzufügen. Dort mussten wir uns jedoch zuerst auf eine Trennung von Haupttitel und Nebentitel einigen. In Bibliotheken wird darüber diskutiert, ob man einen Doppelpunkt benutzt oder einen Punkt. Ich persönlich finde beides schlecht. Ein Doppelpunkt bezeichnet eine Aussage, keine Trennung. Und ein Punkt bezeichnet das Ende eines Satzes. Um Begriffe zu trennen, benutzt man normalerweise (in der Informatik jedenfalls) einen Bindestrich (-) oder einen Unterstrich (_). Wir einigten uns auf die Benutzung eines Bindestriches.
Ich muss sagen, nach erneuter Arbeit mit MARC21, verstärkt sich meine Meinung. MARC21 ist viel zu komplex. Eine Neuerung wäre wirklich hilfreich.
Für die unwahrscheinliche Situation, dass ich jemals mit MARC21 arbeiten muss, gibt es das Tool MarcEdit. (http://marcedit.reeset.net/)
Ich bin mit meiner Meinung jedoch nicht alleine. Es gibt Bibliothekare, die MARC ebenfalls nicht ausstehen können. Ein solcher Artikel hat sogar den tollen Titel “MARC Must Die”. Da kann ich nur zustimmen… (https://hangingtogether.org/?p=6221) (http://swib.org/swib13/slides/malmsten_swib13_136.pdf)
Da wir keine Zeit und Geduld hatten, alle MARC Felder in DC Felder umzuwandeln, stellte unser Dozent wieder ein JSON File zur Verfügung, welches dies für uns erledigte. Dies bedeutete wieder die vorherigen Schritte rückgängig zu machen (warten) und die Änderungen vorzunehmen (warten). Mehrheitlich mussten wir wieder warten. Danach aber konnten wir unsere Testdaten herunterladen und presto. Doch leider hatten wir uns zu früh gefreut und die Datensätze wurden falsch exportiert. Um Zeit zu sparen, stellte unser Dozent uns die Testdaten als TSV-Datei zur Verfügung. Und nun endlich konnten wir mit Solr arbeiten.
Nach dem heutigen Tag war uns allen OpenRefine genauso unsympathisch wie MARC21…
Um die Daten nun in Solr laden zu können, mussten wir zuerst einen Index erstellen. Solr erstellt danach automatisch ein Schema, indem es die Daten analysiert und versucht das Schema selber zu generieren. Leder jedoch gab es beim Importieren eine Fehlermeldung: ein String in einem Feld, wo kein String sein darf.
So mussten wir das Schema manuell anpassen, was glücklicherweise möglich ist. Nachdem wir das korrekte Feld neu konfiguriert hatten, tauchte der nächste Fehler auf. Der Dozent konnte diesen Fehler jedoch einfach beheben, wir nicht, obwohl wir gleich vorgegangen sind. Eine Änderung des Schemas war dann jedoch hilfreich.
Ein Problem hatten wir jedoch noch. Wenn man in unseren Testdaten nach “Einstein” suchte, fand man keine Resultate, was merkwürdig ist, da unsere Testdaten Suchresultate des Begriffes “Albert Einstein” sind. Das Problem konnte jedoch schnell behoben werden. In der Standardkonfiguration gibt es nämlich keine übergreifende Suche. Es müsste immer ein Feld bei der Suche definiert werden. Damit dies nicht nötig ist, definierten wir eine Kopieranweisung aller Werte (*) in das Standard-Feld “_text_”.
Danach mussten wir neu Indexieren und voila. Nun kann man nach Einstein suchen und erhält auch Resultate.
Zum Abschluss schauten wir uns die Testdaten noch genauer an und hielten fest, was alles daran noch geändert werden muss. Da wir alle jedoch nach dem anstrengenden Tag keine Lust mehr auf OpenRefine hatten, erwies sich unser Dozent als gnädig und lies uns eine halbe Stunde früher gehen.
